Acrobat DC ends the dreaded “Renderable Text” Error for Scanned Docs
Acrobat (XI and earlier) sometimes confounded legal professionals during the scanning and OCR process with “renderable text” errors.
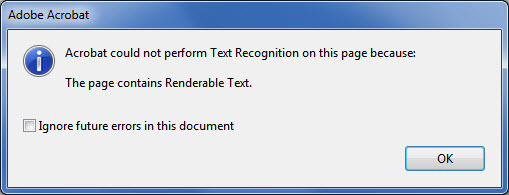
In older versions of Acrobat, if vector text was found outside of the page boundaries, Acrobat would refuse to OCR the document. Here’s the error message you would typically see:
https://blog.adobe.com/media_dfb34f579ef9fb0c2f479f4c21f332845b84108e.gif
{kind=link}
Over the years, I found a variety of odd PDFs from fax systems or other systems that would add vector text or graphics in odd places on the page which would cause errors. At one time, I even helped a small law firm discover that the other side had deliberately embedded vector text to prevent OCR. Ah, the games that get played in discovery, but, I digress . . .
Adobe implemented a partial resolution and I wrote about the fix for the issue in Acrobat 8. This specific fix resolved the problem as long as the renderable vector elements were found within 20% of the page boundaries. However, we still found users that ran into this issue, especially with federal court files which contained vector stamps which sometimes were placed right in the middle of the page.
The good news is that Acrobat DC is can segment image layers from text layers in existing PDFs and OCR the image layer only.
To test this, I created a text comment on top of a scanned PDF, then flattened the file. Note that the text I placed is directly in the middle of the page (see below).

Acrobat OCRd the scanned image layer and the document is completely searchable.
You won’t find this listed among the Acrobat DC new features, but here’s to progress.
Well, uh, it’s almost gone . . .
You might still run into the Renderable Text error if you try to OCR a document which is completely vector-based (an electronic PDF if you will).
An example of a document that will still trigger the error when you try to OCR is a text-only document created in Word and directly output to PDF.
From time to time, a customer will send me a PDF which generates the error. I often discover that the document isn’t a scanned document at all. In that case, you don’t need to OCR the document because all the text is already searchable.