連載
この連載は、現在のウェブ制作における分業体制を前提に、情報設計に関わる「デザインドキュメント」をきちんと制作することで、受託側と発注側のミゾを埋める手段を探ります。
前回は、理想の体験を考えるためのシナリオの解説と作成方法、さらにKPIへの変換方法をご紹介しました。今回はシナリオからワイヤーフレームに進む前に押さえておくべき情報設計の考え方をご紹介します。
前回までで、シナリオを作成したことにより利用シーンや理想の行動は明らかになりました。ここからは、そのシナリオを実現するために、どんなコンテンツをどのような形で画面に配置すれば良いのか、すなわちサイト設計および画面設計を考えていくことになります。
典型的には、以下のような工程で詳細を詰めていくことが多いでしょう。
- 既存コンテンツの棚卸しと整理:コンテンツインベントリなどの方法を使って、ウェブ上に存在するもの以外も含めて既存コンテンツの棚卸し、フォーマットの整理、取捨選択を行います
- サイト構造の検討:サイトマップを作成し、シナリオをサポートできるような階層型構造を検討します
- ナビゲーションの検討:グローバルナビゲーション、ローカルナビゲーションといったナビゲーションパターンを組み合わせて、目的のコンテンツに到達できるようにします
- 画面テンプレートの作成:ナビゲーションとコンテンツエリアのパターンをワイヤーフレームとして起こし、情報の種類に応じて複数のテンプレートを作成します
こういった設計のフェーズにおいて、気をつけるべき大きなポイントがひとつあります。それはサイト構造を考える際に、特定のシナリオに書かれた通りの手順「以外も」満たせる設計にする必要があるということです。ウェブにおいては、ユーザーは直接目的の情報に到達し、さらにその目的自体を調整しながら探索していくからです。
トップダウン型アプローチ依存からの転換
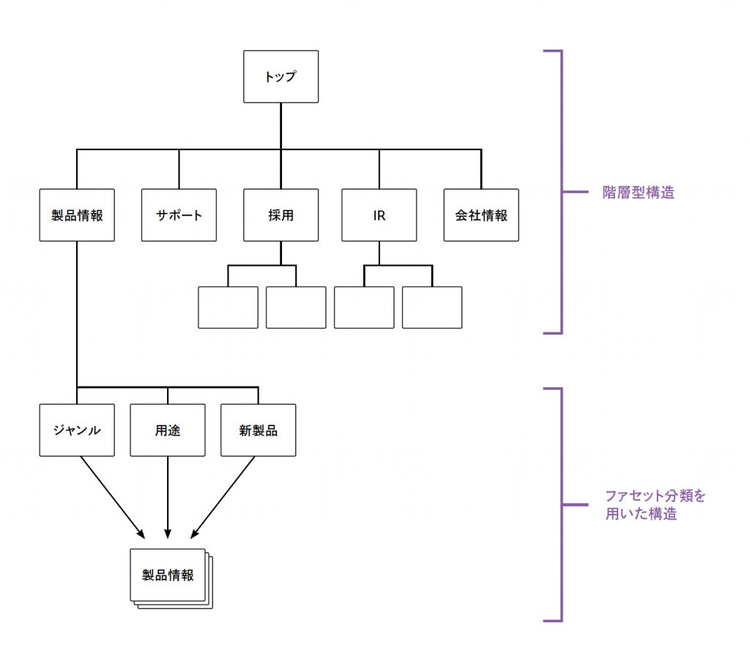
「サイト構造の検討」の段階においてユーザーがどのような情報を探しているかを考え、それを入り口から振り分けて順番に満たしていくという設計方法は、「トップダウン型の構造化アプローチ」と言われています。
ユーザーの情報の探し方、すなわちシナリオからサイト構造を考えていくと、ユーザーの目的ごとにカテゴリを設け、その中にページを配置していくといった階層型の構造になるケースが多いでしょう。階層構造は非常に一般的な構造であるため、ユーザーがサイト構造や現在地を理解しやすいというメリットを持ちます。
トップダウン型のアプローチは、以下のようなサイトでよく使われます。入り口から入ってきたユーザーを適切に振り分け、ゴールに導くという点が重視されるからです。
- パンフレット的な小規模ウェブサイト
- いくつかのサブサイトをまとめあげるための親サイト
- 各ページが個別のフォーマットであるプロモーションサイト
- 長尺の1ページ+FAQ+申し込みフォームなどで表現されるランディングページ群
しかし、上記以外のほとんどのウェブサイトでは、こういった階層型の構造とそれを示すページベースのサイトマップだけでは、求められる役割を果たすように設計することは難しいと感じています。ユーザーは検索エンジンによってウェブサイト内の目的の情報に直接到達し、またサイト内を探索しながらユーザーの中で目的が再設定されます。そのため、そういった行動を含めてサポートできる設計をすることが重要になります。
ウェブでは直接目的の情報に到達する
階層型では、トップページから順に下の階層に降りていくユーザーがイメージされがちですが、そのような使われ方になるケースは実際には多くありません。
トップページに訪れるのは、検索エンジンからブランド名や会社名などを名指しで検索した場合や、他サイトからのリンクがほとんどです。サイトによって異なりますが、私がこれまで関わってきたウェブサイトの場合、トップページへの流入は全体の2〜3割でした。
一方、社名と他のキーワードの組み合わせで検索した場合は、階層の中間ページや、末端の詳細ページにランディングすることになります。また、SNS経由で流入する場合も、シェアされたページに直接ランディングすることが多いでしょう。
ウェブサイトはどこが入口になるのかを制御できません。そして、色んな方向から流入するチャンスがあることは、アプリと比較したウェブサイトの強みです。
ユーザーは目的を調整しながら探索する
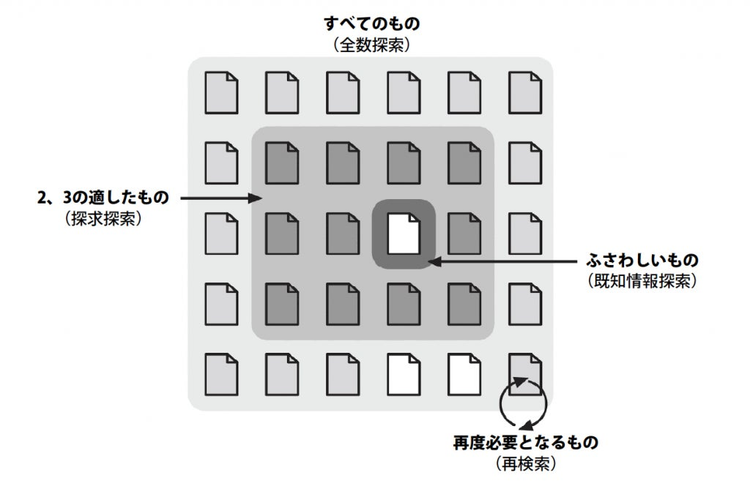
ユーザーは一直線にゴールに向かうわけではありません。ランディングしたあとの探し方も一様ではなく、実際には探索行動は多数のパターンがあります。『情報アーキテクチャ』では以下の4パターンの探し方を紹介しています。
- 既知情報探索:すでに自分が探したいものがなにか、どこで探せばいいのかがはっきりしている場合
- 探求探索:自分が本当に探しているものを把握しておらず、いくつかよい結果を得たら、それを踏み台に次の情報を探す。終わりがはっきりしていない
- 全数探索:特定のトピックに関するものは何もかも、一つ残らず探す。さまざまな用語を切り替えながら忍耐強く検索を続ける
- 再検索:これまでに見つけたものを再度探し直す
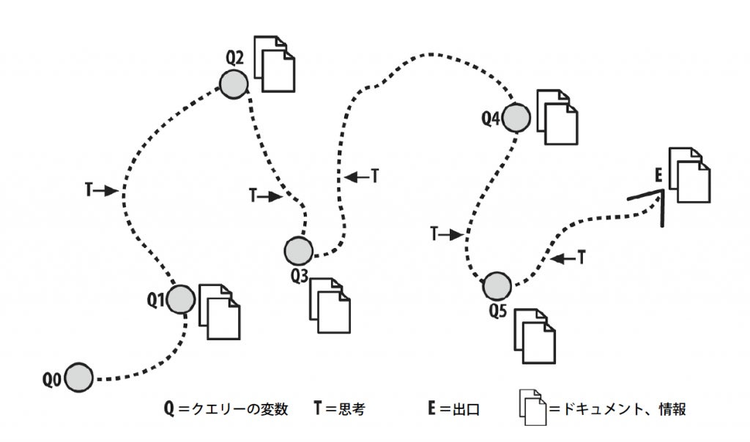
特に探求探索では、ウェブでの検索や、誰かに質問するといった方法を組み合わせて、満足する答えに至るまで発展的に探索が続けられます。このような情報探索行動を表現したものに「ベリー摘みモデル」があります。(参照:『ベリーピッキングモデルで考える探索と検索』)
ベリー摘みモデルはユーザーが情報ニーズを持つことから始まっています。そしてユーザーは情報要求(クエリー)を公式化し、複雑かもしれない道筋に沿って、情報システム内を繰り返し動き回ります。その中で情報のかけら、「ベリー」をつまみ出していくのです。このプロセスでユーザーは「自分が本当に必要なのは何か」と「そのシステムからそのような情報が得られるのか」をより詳しく知るにつれて、情報のニーズを変更していきます。
『情報アーキテクチャ』より
ボトムアップ型が重視される背景
「ベリー摘みモデル」の探索行動をサポートするサイト構造の典型例には、以下のようなものがあります。
- ファセットがメイン:ひとつのものに対し複数の経路を持つファセット構造がメイン。階層型構造はサイト全体を束ねるサポートとしての存在
- 動的な一覧:クエリに応じて変化する動的な一覧ページによって、探索の糸口を作り、同時に探求探索をサポート
- テーマ単位の詳細情報:ユーザーが外から探す目当てとなるテーマに分けられたコンテンツを適切にページにマッピング
- メタデータによる関連性:メタデータによって、関連するコンテンツをリンク
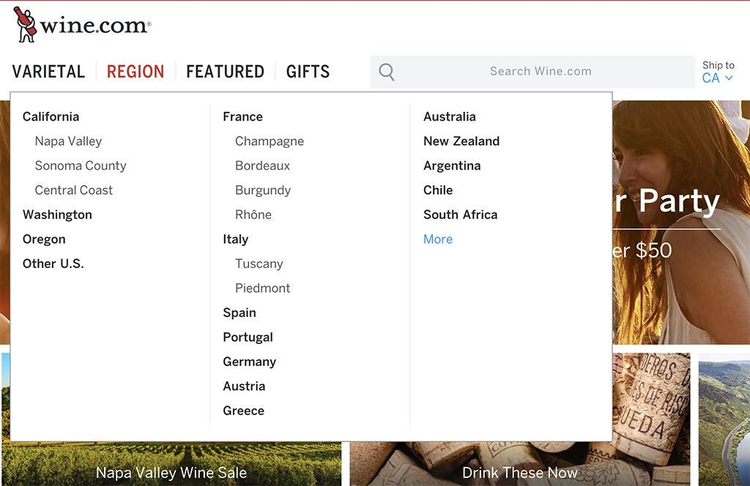
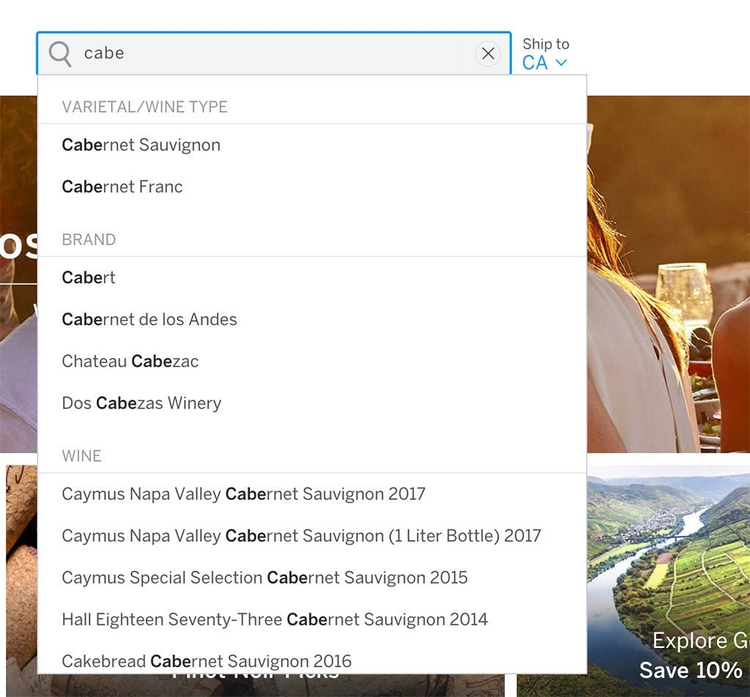
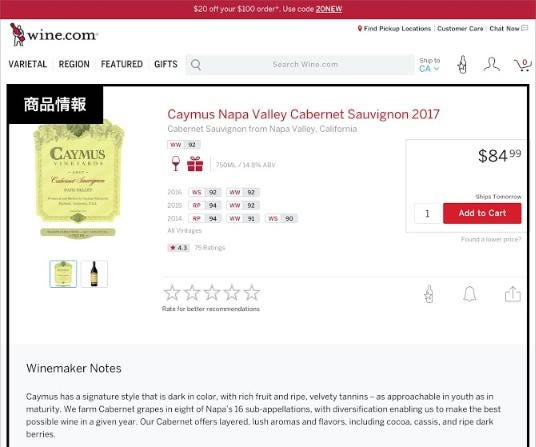
たとえば、古くからファセット構造の代表として語られているwine.com は、さまざまな切り口のナビゲーションを持ち、検索はメタデータによるサジェストがあり、またコンテンツページは関連コンテンツ(商品説明、関連商品、ワイナリー、産地と品種、新着商品)の集合として構成されています。
さらに、こういったコンテンツの一部を切り出し、検索エンジンの結果ページへのスニペットや、SNS向けのOGP、広告テキスト等のかたちで外向けに配置することも、今日のサイト設計では一般的です。
これは、かつてディレクトリ型だったウェブ検索が、コンテンツの爆発的な増加とともに多様な探索をサポートしていく必要性が生じたことにより、データーベース型・ファセット型の構成に変わっていったことと符合していると感じます。Google検索やSNSがある前提で、Web全体がひとつの巨大な検索システム、あるいはキュレーションシステムであるとみなし、そこにどういったコンテンツを置くことで発見され探索されるようにするか、と考えていく必要があります。
このようにコンテンツの関係性を表面化させて、ユーザーの質問に対する答えとして提案するやり方が「ボトムアップ型の構造化アプローチ」です。
ページ単位からコンテンツ単位へ
典型的なサイトマップは、ページを単位として構造を表します。しかし、ボトムアップ型のアプローチでは、コンテンツを多様な形で利用したり、関連する他のコンテンツとつなげます。そのため、ページよりも細かい粒度で、コンテンツが持っているメタデータをもとに多面的なファセット構造を考えなければなりません。ユーザーが興味関心を持つ対象を「オブジェクト」として定義し、それを情報を管理する単位とする必要があります。
検索エンジンやSNSを前提に、どういった要素を置くことで発見され探索されるようになるかを考えるには、ユーザーがどんなテーマで探索するのか?をカテゴリレベルよりも詳細な具体的なキーワードとして考えることになります。そして、そのキーワードに対応するコンテンツは何か?そのコンテンツはどのような属性を持つか?コンテンツ同士はどんな関係性を持つのか?といったことを洗い出し、ファセット構造として成立するように仕上げていきます。
実はCMSで遭遇しているボトムアップ
このように書くと、ボトムアップ型のアプローチが難しそうに感じられるかもしれません。しかし、WordPressなどのCMSを使って以下のような設計を行った経験はないでしょうか?
- 記事を複数カテゴリに所属させる
- カテゴリとは別にタグ付けを行う
- カテゴリ一覧を作り、日付などでソート可能にする
- カテゴリ同士や、コンテンツ同士を関連づける
- カスタムフィールドを使って関連付け用の隠し情報を入れる
- ページテンプレートに関連情報を表示するエリアを設ける
- 関連付けが行われた際の「コンパクトな」コンテンツを別途カスタムフィールドで定義する(本文とは別の概要文やサムネイルを設定する)
- 検索結果ページやOGPとして表示するためのコンテンツのセットを定義する
現在ではCMSを用いたサイト構築が当たり前となっていますが、CMSは本来はページを管理するものではなく、コンテンツを管理するシステムです。
上野学氏は『情報アーキテクチャの新たな領域』(2009)で、CMSの有り様を「コンテンツをデータベースに格納して、表示形式をテンプレートとして別に管理し、様々な状況に応じてこれらを柔軟に組み合わせて出力できるようにすること」と説明しています。
このようなコンテンツの組み合わせをベースとして多面的な探し方を支えるシステムは、まさにボトムアップ型です。だからこそ、初期のSEOにおいて大きな威力を発揮し、セオリーとして定着したと見ることもできます。『いちばんやさしい新しいSEOの教本』では、このアプローチによるサイト構築方法を「正しいSEO」として紹介しています。
次回は、「オブジェクトモデル」という図を通じて、ボトムアップ型のアプローチを実践する方法について説明します。