新機能のスーパー_解像度_は現在Camera Raw 13.2で提供されており、LightroomとLightroom Classicにも近日中に提供される予定です。この記事では、機能自体の説明と動作原理、そしてその活用方法について説明します。
本ブログは、「From the ACR Team(Adobe Camera Rawチーム便り)」と題し、Lightroom、Lightroom Classic、Lightroomモバイル版、Adobe Camera Raw、ならびにPhotoshopのCamera Rawフィルターといった製品のイメージング機能を開発しているチームからのインサイトをお届けする一連のブログ記事の最新版です。筆者は最近、「解像度の強化」に取り組んでいましたが、その詳細についてここで皆さんにご紹介できることを嬉しく思います。このプロジェクトは、アドビリサーチのミヒャエル ガルビ(Michaël Gharbi)とリチャード ジャン(Richard Zhang)との密接な共同作業の成果です。ミヒャエルは以前にも「ディテールの強化」という関連機能を開発しています。
スーパー解像度は現在Camera Raw 13.2で提供されており、LightroomとLightroom Classicにも近日中に提供される予定です。この記事では、機能自体の説明と動作原理、そしてその活用方法について説明します。
まず、私の自己紹介をさせてください。
名前はエリック チャン(Eric Chan)です。これまで13年間アドビで開発に携わってきました。これまでのプロジェクトには、「シャドウ・ハイライト」、「明瞭度」、「かすみの除去」、カメラプロファイル、レンズ補正、「Uplight」などがあります。ここに共通パターンを感じるかもしれませんね。私はピクセルと戯れるのが好きなのです。
スーパー解像度もピクセル操作のプロジェクトですが、これらとはまた別の種類のものです。10メガピクセルの写真を40メガピクセルの写真に変換したり、低解像度カメラで撮影した古い写真を大きなプリント用にサイズアップしてくれたりするような、被写体を拡大してくれる高度な「デジタルズーム」機能があったらと想像してみてください。
他にも想像は膨らみますが、先走ってしまいました。スーパー解像度を正しく理解するためには、まず「ディテールの強化」の話をしなければなりません。
最初のストーリー
2年前、私たちは「ディテールの強化」をリリースしました。これは機械学習を使用して、驚くほどの忠実度でRAWファイルを補間し、アーチファクト(デジタル処理で生じるノイズ)の少ない鮮明なディテールを実現する機能です。詳細についてはこの記事をご覧ください。当時から私たちは、これと同様の機械学習を活用した手法で、これまでにない、エキサイティングな方法で写真の品質を向上させることができるのではないかと考えていました。
その続編の完成
本日ご紹介するのは、その最初のストーリーの続編となる第2の「強化」機能、「スーパー解像度」です。スーパー解像度とは、見かけの解像度を上げることで写真の品質を向上させる処理のことです。写真を拡大処理すると大抵の場合ディテールがぼやけてしまいますが、スーパー解像度には何百万枚もの写真を使ってトレーニングした高度な機械学習モデルが搭載されています。この膨大なトレーニングセットに支えられたスーパー解像度を使えば、エッジをきれいに保ち、重要なディテールを保持したまま、写真をインテリジェントに拡大することができます。
機械学習云々というと複雑に聞こえるかもしれません。実際複雑ではあるのですが、そのテクノロジーをもとに完成したスーパー解像度の機能自体の使い方はとてもシンプルですのでご心配なく。ボタンを押すだけ、あとは10メガピクセルの写真が40メガピクセルの写真に変身するのを見守ってください。キノコを食べたマリオが突然膨張してスーパーマリオになるのと似ていますね、効果音こそありませんが。
でももうピクセル、十分では?
皆さんは、「エリック、もう2021年なのに今さらメガピクセル競争の話?」と思われるかもしれません。最新のカメラには十分以上のピクセルが詰まっていますから。少し前まで私たちが6メガピクセルで十分だと思っていたところ、すぐに12メガが当たり前になり、その後24メガが登場し、今では40メガから100メガものピクセルを撮影できるカメラもあります。それだけのピクセルがあるのに、なぜもっと多くのピクセルが必要なのでしょうか?
答えをひとことで言えばこうです。通常は必要ありませんが、たまに必要になることがあります。そして、本当に本当に必要な時も。
ひとことで済まない答えはこうです。
まず、すべてのカメラが超のつく高解像度を持っているわけではありません。ほとんどの携帯電話は12メガピクセルです。多くのカメラはまだ16~24メガピクセルの範囲にあるといえるでしょう。これは、例えばオンラインでプリントしたり、友人に送ったりするような多くのシナリオでは十分です。しかし、壁に飾る大きなプリントを作成したい場合、エッジをきれいに保ち、ディテールを維持しながら解像度を上げるためにスーパー解像度の機能が役立ちます。後でいくつかの例を見てみましょう。
超メガピクセルの最新型カメラを持っていたとしても、旧式のカメラで撮影した古い写真はどうでしょうか?私のお気に入りの写真のいくつかは、今となっては「たった」8メガピクセルのカメラで15年前に撮影されたものです。これがその一枚です。
以前、この画像を大きくプリントしてみたのですが、結果にはがっかりしました。前景の岩は滑らかになりすぎていて、霧の下から覗く木々はもやもやしていて判別がつかなかったのです。しかし、スーパー解像度のおかげで、質感のある自然な岩や背景の木々をはっきりとした大判プリントに出力できるようになりました。つまり、スーパー解像度は古い写真に新しい命を吹き込むことができるのです。
また、より高い解像度は、タイトに切り取られた写真を扱う際にも便利です。思ったよりも遠くから撮影したために、画像全体に比べて被写体が小さすぎるという状況に陥ったことはありませんか?私にはよくあることです。例を挙げてみましょう。
このハヤブサが頭上を飛んできたので、彼女を見失う前に数枚のフレームを撮影しました。もちろん、その時2xのエクステンダー付き800mmレンズに切り替えられれば良かったのでしょうが、シロハヤブサが現れたのはほんの数秒の間だったのです(そんな高価な機材も実は持っていません)。400mmレンズ装着の1.6xカメラボディでは、トリミング無しの写真は次のような状態でした。
これは私のお気に入りの鳥の写真のひとつですが、上述の撮影状況のために、トリミングするとわずか2.5メガピクセルになってしまいます。そこでスーパー解像度の出番です。私は10メガピクセルの画像を手に入れ、きちんとしたサイズのプリントができるようになりました。このように、スーパー解像度を高度な「デジタルズーム」機能として使うこともできます。
ここまでスーパー解像度の活用法について述べてきましたが、次にこれを実現したテクノロジーについて説明します。
その動作原理は?
スーパー解像度を支えるコアテクノロジーを開発したのは、アドビリサーチのミヒャエル ガルビとリチャード ジャンです。
基本的には、大量の写真サンプルを使ってコンピュータをトレーニングしています。具体的には、低解像度と高解像度をペアにした画像サンプルを何百万セットも用意し、コンピュータに低解像度画像からアップサンプル(高解像度化)する訓練を施したのです。実際に使用した画像は、以下のようなものです。
これらは、実際の写真に含まれている、花や布地、樹木や枝、レンガや屋根瓦などのディテールの領域を128 x 128ピクセルに切り出したものです。あらゆる種類の被写体をカバーするのに十分なサンプルを用意すれば、モデルは最終的に自然な方法で実際の写真をアップサンプルすることを学習します。
コンピュータに何らかのタスクを実行するように教える、というと複雑に聞こえるかもしれませんが、ある意味では子供に教えるのと似ています。どちらも、いくつか学習の筋道と十分な量の例を与えると、少し時間をおくだけで、あとは自分で学習を進められるようになります。私たちがスーパー解像度に与えた基本的な筋道は「深層畳み込みニューラルネットワーク(CNN)」と呼ばれるもので、簡単に言えば、あるピクセルに接する周囲のピクセルがそのピクセルに影響を及ぼす関係性を学習するということです。言い換えれば、特定のピクセルを適切にアップサンプルできるように、その周囲のピクセルを分析してコンテキストを得る方法をコンピュータに学習させるのです。文章内で単語がどう使われているのかを知ることが、単語の意味の学習に役立つのに似ています。
機械学習モデルのトレーニングは計算量の多いプロセスで、数日から数週間かかることもあります。以下に、富士フイルムのX-Trans RAWのパターンを起点にした、機械学習モデルの進捗をご紹介します。
最初の結果(左上と中央上)が笑ってしまうほど悪いことが示されています。どちらも写真にさえ見えませんが、これはトレーニングを始めたばかりの頃に起こることです。子供が生まれてすぐ歩けるようにならないのと同じように、機械学習モデルもすぐにデモザイクやアップサイズをきれいにできるようになるわけではありません。しかし、トレーニングを重ねることで、モデルは急速に改善されていきます。最終的な結果(右下)は、基準画像に非常によく似ています。
私たちのスーパー解像度の訓練方法には、いくつか独自のものがあります。1つめは、大多数のカメラが使用するBayer方式とX-Trans方式のRAWファイルについては、エンドツーエンドで品質を最適化するためにRAWデータから直接トレーニングをおこなっていることです。言い換えれば、RAWにスーパー解像度を適用すると、ディテールの強化という嬉しい効果も同時に得られるということです。2つめのカギとなるのは、リサイズ後にアーチファクトを生じやすい、テクスチャと細かなディテールを多く含む「難度が高い」画像サンプルを重点的に用意してトレーニングをおこなったことです。最後が、CoreMLやWindows MLなどの最新のプラットフォーム技術をフル活用できるように機械学習モデルを構築したことです。これらの技術により、最新のグラフィックプロセッサ(GPU)上でモデルをフルスピードで実行できます。
使い方は?
スーパー解像度の使い方は簡単です。写真を右クリックして(またはControlキーを押しながらクリックをして)、コンテキストメニューから「強化…」を選択します。「強化のプレビュー」ダイアログボックスで、「スーパー解像度」ボックスにチェックを入れて、「強化」をクリックします。
コンピュータが「考え中」モードに入り、膨大な計算の後に、Digital Negative(DNG)形式の新しいRAWファイルを作成します。元の写真に加えられた調整は、スーパー解像されたDNGにも自動的に反映されます。その後は他の写真と同じように、好きな調整やプリセットを適用して編集することができます。編集といえば、スーパー解像後に「シャープ」または「ノイズ低減」あるいは「テクスチャ」を調整することも考慮してみてください。これらのコントロールはすべてディテールに影響を与えるものなので、スーパー解像された写真で最高の結果を得たいときに、そのような調整が効果的な場合があります。
スーパー解像度では、写真の線形解像度を2倍にします。これは、元の写真の幅と高さが2倍、または総ピクセル数が4倍になることを意味します。たとえば、次のソース写真は16メガピクセルなので、スーパー解像度を適用すると64メガピクセルのDNGになります。
現在、スーパー解像度を適用可能な画像は、長辺が65,000ピクセルまたは総画素数500メガピクセルに制限されています。巨大なパノラマなど、この数字に近いファイルにスーパー解像度を適用しようとすると、結果が大きすぎるためにエラーメッセージが表示されます。私たちは将来的にこれらの制限を拡大する方法を検討していますが、あまり心配しないでください。500メガピクセルのファイルは今でもかなり大きな部類に入ります。
Bayer方式またはX-Trans方式のRAWファイルにスーパー解像度を適用すると、自動的にディテールの強化も適用されます。この組み合わせで、より高い品質とパフォーマンスが得られます。
スーパー解像度は、JPEG、PNG、TIFFなどの他のファイル形式にも対応しています。ここでは、タイムラプスのシーケンスをRAWフォーマットでキャプチャし、Photoshopで合成してTIFFファイルとして保存しました。そこにスーパー解像を適用した例がこれです。
強化をよく使う方は、次のヒントを参考にすると、ワークフローが早くなるかもしれません。フィルムストリップの中から目的の画像をすべて選択して「強化」コマンドを実行すると、複数の画像に一度に処理を適用できます。ダイアログには最初の写真のプレビューのみが表示されますが、処理は選択済みのすべての写真に適用されます。「強化」メニューコマンドを選択する前に「Option」キー(macOSの場合)または「Alt」キー(Windowsの場合)を押すと、ダイアログを完全にスキップすることもできます。この「ヘッドレス」オプションを使用すると、以前に指定されていた「強化」設定が適用されます。
比較
スーパー解像度の結果を詳しく見てみましょう。まずは、dpreview.comで公開されているスタジオテストシーンから始めます。
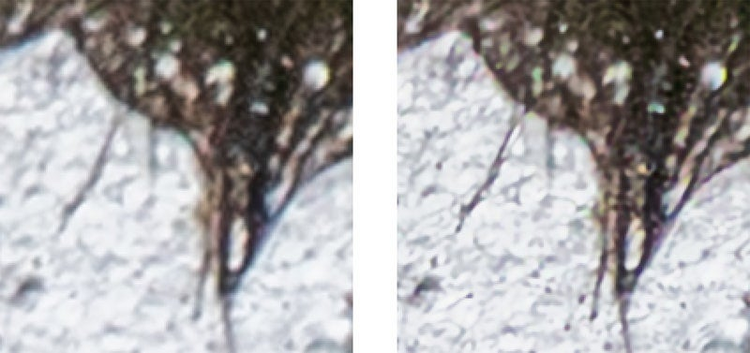
これは明らかに自然に撮影された写真ではありませんが、従来のアップサイズ方法と比較したスーパー解像度のメリットを理解するために取り上げました。以下は、このテストシーンの様々な部分をズームインしてトリミングしたものです。左の画像は標準的なバイキュービック法によるアップサイズを使用しており、右の画像はスーパー解像度を使用しています。新しい方法では、細かいディテールや色の保存に優れた効果を発揮していることに注目してください。
それでは、より一般的な風景写真の例を見てみましょう。
これは、下の図でわかるように、大きなシーンからかなりタイトに切り抜いたものです。
これは、枝や葉の部分にズームインして比較したところです。左がバイキュービック法で、右がスーパー解像度です。
彼女はベニザケ獲りに夢中ですが、腹ペコのクマを邪魔するのは危険なので、私はこのヒグマから離れたところにいました。下図は毛皮と水しぶきのクローズアップで、左がバイキュービック法、右がスーパー解像度です。
ベストプラクティス
ここでは、スーパー解像度を最大限に活用するためのヒントをいくつか紹介します。
可能な限り、RAWファイルを使用してください。一般的には、利用可能な最もクリーンなソース写真から始めます。元の写真にアーチファクトがある場合、高圧縮されたJPEGやHEICファイルによく見られるように、スーパー解像度を適用した後にアーチファクトが目立ちやすくなることがあります。
GPUが高速であればあるほど、結果も速くなります。ディテールの強化とスーパー解像度は、どちらも何百万回もの計算を行い、高速なGPUの恩恵を大いに受けます。ラップトップをお使いなら、外部GPU(eGPU)が大きな違いをもたらします。1枚の画像の処理にかかる数分を数秒にまで短縮できます。
新しいコンピュータやGPUをお探しの方には、CoreMLやWindows MLの機械学習技術に最適化されたGPUモデルをお勧めします。例えば、Apple M1チップのNeural Engineは、CoreMLの性能に合わせて高度にチューニングされています。同様に、NVIDIAのRTXシリーズのGPUのTensorCoresは、Windows MLを非常に効率的に実行します。GPUの状況は急速に変化しており、私は大きなパフォーマンスの向上を期待しています。
スーパー解像度は非常に大きなファイルを生成し、ディスクからの読み込みに時間がかかります。私は、ソリッドステートドライブやSSDのような高速ドライブを使用することをお勧めします。
最後になりますが、すべての写真にスーパー解像度を適用する必要はありません。特別な写真や、本当に必要なプリントプロジェクトのための新しいオプションだと思ってください。10万枚もの写真をカタログしている私でも、スーパー解像度を使ったのはほんの一握りです。ネコの写真を何枚も100メガピクセルにする必要は実はない、というのが長く慎重な検討の結果です。いや本当に。
今後の展望
私たちの「強化」機能の第一弾がディテールの強化で、続く第二弾がスーパー解像度でした。現在、スーパー解像度をさらに発展させ、より大きく、よりきれいな結果が得られるようにする方法を検討しています。また、「シャープ」や「ノイズ低減」の強化など、同じ基盤技術を応用した他の可能性も模索しています。画像の見栄えを良くできる可能性があれば、それが何であっても私たちは挑戦していきます!
この記事は2021年3月10日(米国時間)に公開されたFrom the ACR team: Super Resolutionの抄訳です。