빅데이터에서 유실된 정보를 찾는 방법

빅데이터의 가치는 포함하고 있는 정보 그 이상도 이하도 아닙니다. 데이터가 제시하는 결과가 비즈니스, 날씨, 스포츠든지 또는 양자 물리학에 관한 것이든지 정보를 활용하여 불확실성을 제거하기 때문입니다. 빅데이터 정보로 사람들은 보다 현명한 의사결정을 내릴 수 있고 기술은 보다 효과적으로 알고리즘을 수행할 수 있습니다.
수집된 데이터의 품질, 가공 방법, 분석의 정확도 등 수많은 요인에 따라 데이터가 포함해야 하는 정보의 양이 달라집니다. 대용량의 데이터 세트에서는 데이터의 양이 증가할수록 불확실성이 증가하여 데이터의 품질이 떨어지고, 결과적으로 현명하지 못한 의사결정으로 이어지는 경우도 생깁니다. 특히 데이터에 결함이 있거나 파편화되어 있는 경우 더욱 그렇습니다.
‘지나치게 과다한 정보’가 있을 수 있나요?
먼저, “얼마나 많은 정보가 필요합니까?”라는 질문에 답해야 합니다. 용도에 필요한 실제적인 수준을 넘어서는 많은 정보가 존재하기 때문입니다. 스위스 제네바에 있는 대형 강입자 충돌기의 입자 검출기는 극 소립자의 운동량까지 매우 정밀하게 측정한다지만, 우리는 가끔 투수가 던진 공이 운동량을 떠나 볼인지 아니면 스트라이크인지만 알고 싶어 합니다.
필요한 정보의 양을 알았다면 이제 데이터에서 정보가 유실되는 지점을 조사해야 합니다. 최대한 많은 정보를 수집하는 것을 돕기 위해 정보 손실의 주요 원인을 다음 이미지로 나타냈습니다.
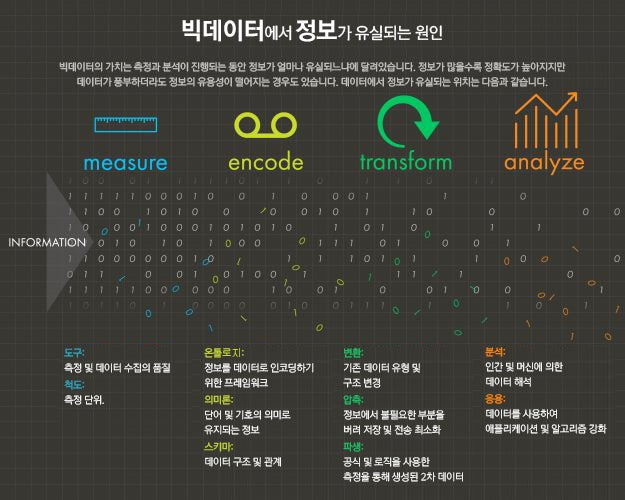
인간과 기술의 세계에서 측정의 산물로 데이터가 생성됩니다.
고도의 측정 도구를 통해 확보된 데이터는 정확도는 높고 불확실성은 낮은 정보들을 제공합니다. 뛰어난 측정 도구일수록 측정하고자 하는 전체 사건 대비 많은 수의 사건 정보를 수집할 수 있으며, 보다 세밀하게 측정 대상을 묘사할 수 있습니다. 다음과 같은 일상적인 예를 통해 측정 품질이 정보의 가치에 미치는 영향을 생각해 볼 수 있습니다.
- 주행 자동차의 속력
- 디지털 미디어 플레이어로 재생되는 동영상 수
- 기압
- 하루에 걷는 걸음 수
이와 같은 각각의 예에서, 서로 다른 측정 도구는 서로 다른 정확도를 가질 수 있습니다. 예를 들어 속도계는 타이어 회전수를 기준으로 자동차의 속도를 계산합니다. 정상적인 조건에서 속도계는 실제 속도의 2% 오차범위 내의 측정 데이터를 제공하지만 타이어 직경과 환경 조건이 변하면 속도계의 측정 데이터는 실제 속도와 10% 이상 오차가 납니다. 경찰관은 전자기파를 사용해 자동차의 속도를 측정하는 데, 이러한 도구도 측정 품질에 따라 많은 영향을 받습니다. 이것으로 실제 속도에 대한 보다 정확한 정보를 확보하는 것이 중요한 이유를 알 수 있습니다.
측정이 더욱 세밀해질수록 정보의 양이 증가합니다. 측정 척도의 예에는 기간(매일, 매시, 매초 등)과 위치(시/도, 공간 좌표 등) 척도 등이 있습니다. 시간과 장소에 대한 정보는 많을수록 좋지만 대상을 보다 세밀하게 측정할 때 데이터 양이 급격하게 증가합니다. 우리 자신을 예로 들어 볼까요? 이름, 주소 및 결제 방법 정도면 우리가 매일 사용하는 대부분의 서비스(예: 유틸리티, 미디어 구독 등)를 제공받고 대부분의 제품을 구매하기 위한 정보로는 충분합니다. 이보다 더 세부적으로 데이터를 측정하면 연령, 성별, 취미, 미디어 소비, 소비 특징 등 마케터가 특히 가치 있다고 판단하는 정보가 드러나게 됩니다. 그러나 개개인에 대한 정보는 이보다 훨씬 더 세밀해질 수 있습니다. 측정의 목적이 건강을 위한 것이라면 올바른 치료법을 처방하기 위해 충분한 정보를 확보해야 하며, MRI 또는 CT 스캔이 동원될 수 있습니다. 따라서 올바른 측정 척도는 데이터를 수집하려는 목적에 따라 달라질 수 있습니다.
보다 세밀한 도구를 통해 적합한 수준의 척도로 데이터를 측정하면 필요한 정보를 최대한 확보할 수 있습니다. 이런 과정을 거쳐야 데이터의 불확실성을 줄이고 의사결정에 필요한 가장 가치 있는 데이터가 탄생하는 것입니다.
블로그 전문은 여기에서 확인하실 수 있습니다.